“THE SUN GOES AROUND THE EARTH”
If one grew up in the city of Kolkata in the 1980s and 90s, they would not be unfamiliar with the above graphiti planted on innumerable walls and lamposts. The graphiti and the adamant proponent of this theory is a legend that a generation would remember.
I was reminded of this, by a rather unfortunate turn of events that happened, on a mailing list of much repute. Just this morning, I was speaking with a colleague about how often and unknowingly we are drawn into stressful situations which make us lose focus from the task at hand. After having responded to a mail thread now crossing the 80+ mark, I wanted to step back, summarize and review this entire situation.
It all started when someone, who by his own admission is not a native speaker of Bangla/Bengali language, wanted to transcribe Sanskrit Shlokas (hymns) in the Bangla script into a digital format and requested for modifications in a in-use keymap. To what final end, is however unclear. This is not an unusual practice as there are numerous books and texts of Sanskrit that have been written in the Bengali script and this effort can be assumed as a natural progression to digitizing texts of this nature. What stands out is the unusual demand for the addition of a certain character, which is not part of the Bengali script, into a Bengali keymap (much in use) that this gentleman wanted to use to transcribe them. The situation worsens with more complications because this character is not a random one and belongs to the Assamese script.
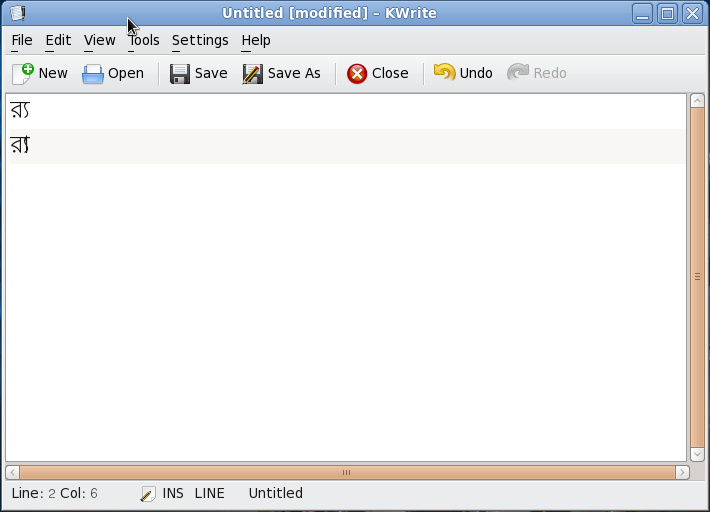
The character in question is the Assamese character RA, written as ৰ and has the Unicode point U+09F0. This is part of the Unicode chart for the Bengali script, which is used to write Bengali, Assamese, and Manipuri (although Meitei is now the primary script for Manipuri). Although exclusively used for Assamese, this character does have a historical connection with the Bengali script. ৰ was also used as the Bengali character RA before the modern form র (Unicode point U+09B0) came into practice. At which exact point of time this change happened is somewhat unclear to me, but references to both the forms can be found as early as 1778 when Nathaniel Brassey Halhed published the A Grammar of the Bengali Language. Dr.Fiona Ross‘ extensively researched The Printed Bengali Character: Its Evolution contains excerpts from texts where the ancient form of র i.e. ৰ has been used. However, this is not the main area of concern.
Given its pan-Indian nature, Sanskrit has been written in numerous regional scripts. I remember, while at school Sanskrit was a mandatory third language of study. The prescribed book for the syllabus used the Devanagari script. On the other hand, the Sanskrit books that I saw in my home were in the Bengali script (some of my ancestors, including my maternal Grandfather were Priests and Sanskrit teachers who had their own tol). Anyway, I digress here. The main concern is around the two characters of ‘BA‘ and ‘VA‘ . In Devanagari, ‘BA‘ i.e. ब and ‘VA‘ i.e. व are two very distinct characters with distinct pronunciations. While ‘BA‘ ब is used for words that need a pronunciation such as बालक (phonetic: baa-lak), ‘VA‘ व is used for words such as विद्या (phonetic:weedh-ya). In Bengali, these two variations are respectively known as ‘Borgiyo BA‘ and ‘Antastya BA‘. However, unlike Devanagari they do not have separate characters. So both of them are represented by ব (U+09AC in the Unicode chart). Earlier they held two different positions in the alphabet chart, but even that has been relinquished. The pronunciation varies as per the word, a practice not dissimilar to the behaviourial aspects of the letters, ‘C‘ and ‘T‘ in English.
This is where it starts getting muddled. The gentleman in question requests for a representation of the Devanagari equivalent of the separation of BA and VA, for Bengali as well. Reason stated was that the appropriate pronunciations of the Sanskrit words were not possible without this distinction. So as a “solution” he suggested the use of the Assamese RA glyph in place of the Borgiyo BA sounds and the Bengali BA to be reserverd exclusively for the lesser used Antastya BA i.e. VA sounds. Depicted below as a diagram for ease of reference.

On the basis of what legacy this link is to be established or how the pronunciation for the two characters have been determined, meets a dead end in the historical references of the Bengali script[1].
To support his claims he also produces a set of documents[1][2] which proudly announces itself as the “New Bengali character set” (নূতন বর্ণপরিচয়/Nutan Barnaparichay) at the top of the pages. The New Bengali character set seems quite clandestine and no record of it is present in the publications from the Paschimbanga Bangla Academy, Bangla Academy Dhaka or any of the other organisations that are considered as significant contributors for the development and regulation of the language. Along with the New character set, there are also scanned images from books where the use of this character variation can be seen. However the antecedents of these books have not been clearly identified. In one of them, the same word (বজ্র) has been spelt differently in two sentences, which imho adds more confusion to the melee.
On my part, I have also collected some excerpts from Sanksrit content written in Bengali, with particular emphasis on the use of ব. Among them is one from the almanacs (ponjika) which are widely popular amongst householders and priests in everyday reference of religious shlokas and hymns.
The character in the eye of the storm i.e. the Assamse RA and its Bengali counterpart are very special characters. These form two different conjuncts each with the ‘YA’ (U+09AF that is shared by both the scripts) without changing the sequence of the characters:
র + য = র্য
র + য = র্য (uses ZWJ)
ৰ + য = ৰ্য
ৰ + য = ৰ্য (uses ZWJ)
The Bengali character set as we know it today was created by Ishwar Chandra Bidyasagar, in the form of the বর্ণপরিচয়/Barnaparichay written by him. Since much earlier, the script also saw modern advancements mostly to cater to the requirements of the printing industry. His reforms added a finality to this. The বর্ণপরিচয়/Barnaparichay still remains as the first book that Bengali children read while learning the alphabets. This legacy is the bedrock of the printed character and, coupled with grammar rules, defines how Bengali is written and used since the last 160 years. The major reform that happened after his time was the removal of the character ঌ (U+098C) from everyday use. Other than this, the script has remain unchanged. In such a situation, a New Barnaparichay with no antecedents and endorsements from the governing organisations cannot shake the solid foundations of the language. The way the language is practised allows for some amount of liberty mostly in terms of spellings mainly due to the legacy and origins of the words. Some organisations or publication houses prefer to use the conservative spellings while others recommend reforms for ease of use. The inevitable inconsistencies cannot be avoided, but in most cases, the system of use is documented for the reader’s reference. Bengali as a language has seen a turbulent legacy. An entire nation was created from a revolution centered around the language.
During this entire fiasco the inputs from the Bengali speaking crowd (me included) were astutely questioned. Besides the outright violation of the Bengali script, complications arising out of non-standard internationalized implementations which were highlighted, were waived off. What is more disappointing is the way the representatives from IndLinux handled the situation. As one of the pioneering organisations in the field of Indic localization they have guided the rest of the Indic localization groups in later years. With suggestions for implementing the above requests in the Private Use Area of the fonts (which maybe a risky proposition if the final content, font and keymap are widely distributed) and providing customized keymaps they essentially risked undoing critical implementational aspects of the Bengali and Assamese internationalization. Whether or not the claims from the original requestor are validated and sorted, personally I am critically concerned about the advice that was meted out (and may have also been implemented) by refuting the judgement of the Bengali localization teams without adequate vetting.
Note:A similar situation was seen with the Devanagari implementation of Kashmiri. Like the Bengali Unicode chart, the Devanagari chart caters to multiple languages including Hindi, Marathi, Konkani, Maithili, Bodo, Kashmiri and a few others. Not all characters are used for all the languages. While implementing Kashmiri, a few of the essential characters were not present in the Devanagari chart. However, similar looking characters were present in the Gurumukhi chart and were used while writing Kashmiri. This was rectified through discussions with Unicode, and the appropriate code points were alloted in the Devanagari chart for exclusive use in Kashmiri.










![[1]](http://www.indlinux.org/wiki/index.php/File:Complete_Shriiharsa_Lipi,_50_letters_-_2.jpg){kind=link}
![[2]](http://www.indlinux.org/wiki/index.php/File:Complete_Shriiharsa_Lipi,_50_letters_-_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}